
December 3, 2025
March 2, 2026
How Do I Run Blue‑Green or Canary Deployments on a Budget

Fear is the silent killer of software velocity.
Founders often obsess over customer acquisition costs or churn rates. They ignore the financial hemorrhage caused by a fragile deployment pipeline. When an engineering team fears pressing "deploy," innovation stalls. Features sit in staging environments. They rot. Value fails to reach the customer. This is not merely a technical inefficiency. It is a capital allocation failure.
Data illuminates the severity of this issue. Gartner estimates the average cost of IT downtime at $5,600 per minute. That figure captures only the immediate revenue loss. It fails to account for the reputational damage or the engineering hours burned on emergency hotfixes.
Most executives believe the solution lies in expensive enterprise tools. They assume safety requires a Google-sized budget. They believe "Blue-Green" or "Canary" deployments are luxuries reserved for the Fortune 500.
This belief is false.
Safety does not require infinite resources. It requires deliberate architecture. A startup can achieve zero-downtime releases on a shoestring budget. It requires shifting focus from buying tools to building systems. The cost of operating without this system is high. It manifests as slow release cycles. It shows up as developer burnout. It ultimately results in a product that cannot keep pace with the market.
This article deconstructs the mechanics of high-availability deployments. It outlines how to implement them without bloating the AWS bill. It turns deployment from a moment of terror into a non-event.
Decoupling Release from Risk
Deployment and release are distinct concepts. Deployment is the technical act of moving code to a server. Release is the business act of exposing that code to a user. Conflating these two creates risk.
The objective of affordable deployment strategies is to separate these events. This allows the system to fail without the customer noticing.
1. The Geometric Logic of Blue-Green Deployments
The Blue-Green model is binary. Two identical environments exist. "Blue" takes live traffic. "Green" hosts the new version. The switch happens instantly at the load balancer level.
The misconception is that this requires double the infrastructure cost. This is only true if the environments run at full capacity 24/7. In a lean model, the "Green" environment is ephemeral. It spins up only during the deployment window.
The Mechanics of the Swap:
- Infrastructure as Code (IaC): Scripts define the server configuration.
- The Switch: The router points traffic from Blue IP to Green IP.
- The Fallback: If Green fails, the router points back to Blue immediately.
The cost is negligible. It is the price of running duplicate servers for thirty minutes rather than thirty days.
2. The Statistical Safety of Canary Releases
Blue-Green is an on/off switch. Canary releases are a dimmer switch.
A Canary release exposes the new version to a small subset of users. It validates stability before a full rollout. Enterprise tools use complex algorithms to manage this. A budget approach uses simple headers or cookies.
The Budget Canary Implementation:
- User Segmentation: Identification of a low-risk user group. This might be internal staff or free-tier users.
- Traffic Routing: A lightweight proxy (like NGINX or HAProxy) routes 5% of traffic to the new cluster.
- Verification: Monitoring tools check for error spikes in that 5%.
- Promotion: If the error rate remains stable, traffic increases to 100%.
3. The Database Bottleneck
The hardest part of these strategies is not the code. It is the data. Code is stateless. Databases have state.
If the Green version changes the database schema, the Blue version might break. The solution is the Expand-Contract Pattern.
- Expand: Add new columns or tables without removing old ones. Both Blue and Green can read the database.
- Migrate: Update the code to write to the new structures.
- Contract: Once Blue is retired, remove the old columns.
This requires discipline. It does not require money. It forces engineers to think about backward compatibility. This is a cultural shift.
4. Second-Order Effects of Systematization
Implementing these systems creates value beyond uptime.
- Developer Confidence: Engineers ship faster when safety nets exist.
- Recruitment: Top talent prefers working in professional environments. They avoid companies where deployments require "all hands on deck" at 2 AM.
- Compliance: Auditable deployment trails are essential for SOC2 and ISO certifications.
Real-World Application
Theory means nothing without execution. Two case studies illustrate the divergence between systematic and reactive leadership.
Case Study A: The Systematizer
The Context: Company who provided a B2B SaaS platform for logistics. They served enterprise clients with strict SLAs. Downtime meant penalties.
The Challenge: The engineering team had a limited budget. They could not afford a managed Kubernetes service or high-end deployment platforms like Harness or Octopus Deploy. They deployed once every two weeks. Deployments took four hours.
The System Approach:
The Founder refused to buy more servers. She invested in the process.
- The "Poor Man's" Blue-Green: They used a simple DNS swap strategy. They spun up a new set of cheap instances (Green) containing the new build.
- The Validation: An automated script ran smoke tests against Green.
- The Switch: They updated the DNS record to point to Green.
- The Cost: The extra instances ran for one hour per deployment. The total cost was less than $50 per month.
The Result:
The company moved to daily deployments. The feedback loop shortened from 14 days to 24 hours. They caught bugs before they hit the entire user base. Sarah scaled the company to a $50M exit because the technology was an asset, not a liability.
Case Study B: The Instinct-Led
The Context: Business was a rapid-growth e-commerce plugin. They had heavy traffic and aggressive feature goals.
The Challenge: The Founder believed in "moving fast and breaking things." He viewed deployment pipelines as "over-engineering."
The Instinct Approach:
He trusted his lead developer's gut. They deployed directly to production during low-traffic windows. They relied on manual testing.
- The Incident: On Black Friday, they pushed a hotfix for a checkout bug.
- The Failure: The fix introduced a database lock. The entire site froze.
- The Recovery: Without a Blue environment to switch back to, they had to debug in production. It took four hours to restore service.
The Result:
They lost $120,000 in transaction fees. They lost three major partners. He burned out his lead engineer, who quit the following week. The lack of a system became the ceiling on their growth.
The Founder’s Quarterly Action Plan
Transforming deployment culture takes time. It requires a phased approach. This plan transitions a team from reactive chaos to systematic precision over 90 days.
Phase 1: Audit and Foundation (Weeks 1-4)
The goal of this phase is visibility. You cannot optimize what you do not measure.
- The Infrastructure Audit: Map every server and service. Identify where hard-coded IP addresses exist. These are the enemies of Blue-Green deployments.
- The Metric Setup: Install basic observability. Use open-source tools like Prometheus or the free tiers of Datadog. You must see error rates and latency in real-time.
- The Scripting Initiative: Forbid manual server configuration. Every server setup must be a script. If it is not in code, it does not exist.
Phase 2: Structured Experimentation (Weeks 5-8)
The goal of this phase is risk-free practice.
- The Internal Canary: Configure the load balancer to route traffic based on IP address. Route the office IP to the new version. Everyone else sees the old version.
- The "Dark" Launch: Deploy the new code but keep the features turned off using Feature Flags. This tests the deployment mechanics without testing the user experience.
- The Rollback Drill: Intentionally break the Green environment in staging. Time how long it takes to switch traffic back to Blue. The target is under 60 seconds.
Phase 3: Reinforcement and Automation (Weeks 9-12)
The goal of this phase is removal of human intervention.
- Automated Traffic Shifting: Write scripts to gradually increase traffic to the Green environment. 10%, then 50%, then 100%.
- Automated Termination: Configure the system to automatically kill the Blue environment one hour after a successful switch. This prevents cost leakage.
- The Documentation Lock: Update the developer handbook. The new process is now the only process.
Founders often hold limiting beliefs about technical operations. These myths prevent them from adopting affordable deployment strategies.
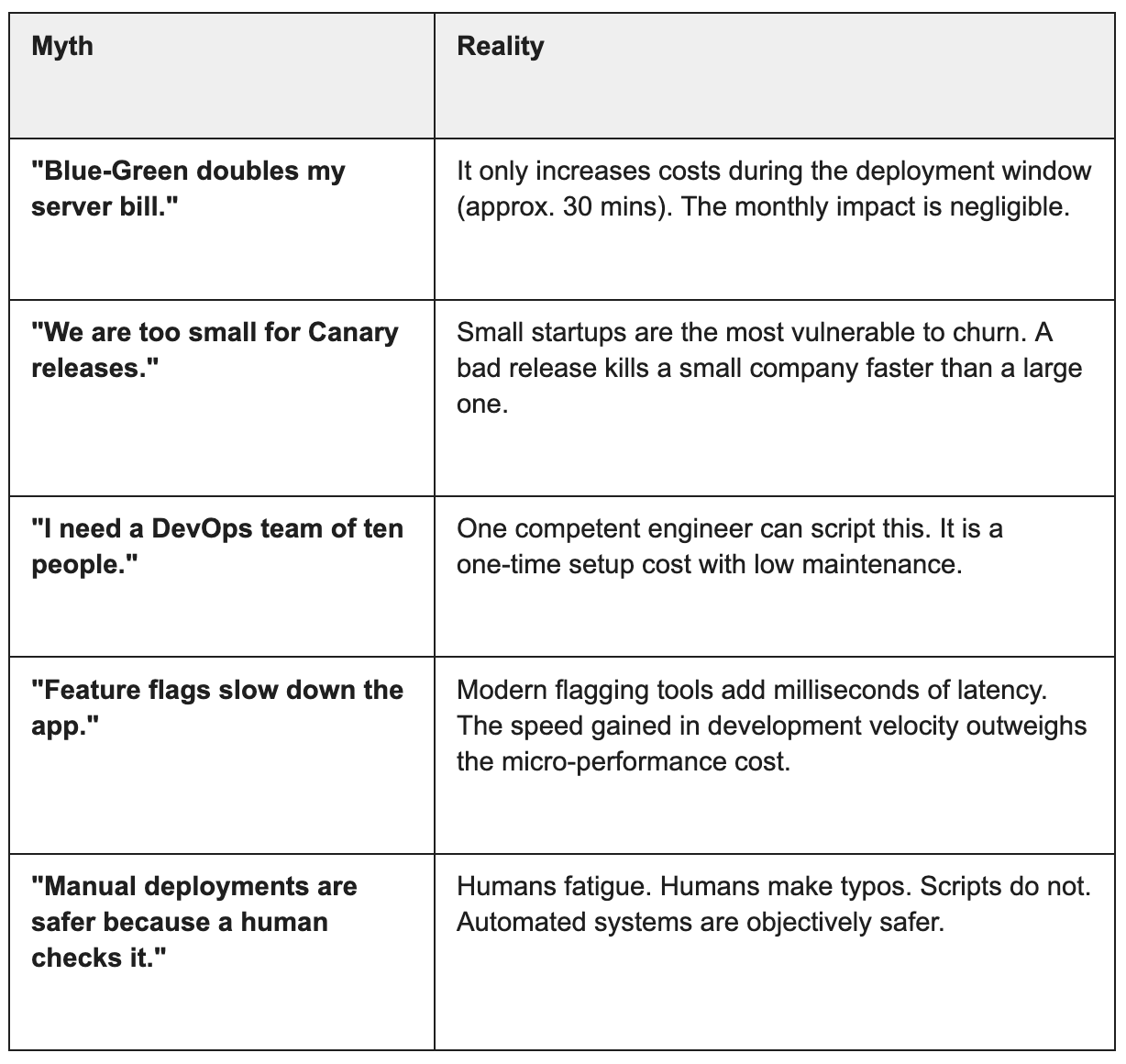
72-Hour Reset
Deployment is not a technical detail. It is the heartbeat of a digital company. A healthy heartbeat allows for exertion, growth, and speed. An irregular heartbeat creates anxiety and limits capacity.
Affordable deployment strategies like Blue-Green and Canary are accessible to every company. They require architectural discipline, not a blank check. They shift the organization from a stance of fear to a stance of aggression.
The difference between the Systematizer and the Instinct-Led founder is not intelligence. It is the willingness to do the boring work of building a safety net.
The 72-Hour Reset:
Take these three steps immediately.
- Day 1: The Cost Analysis. Calculate the cost of your last three incidents. Include engineering time and estimated lost opportunity. Present this to the team to create urgency.
- Day 2: The Tool Audit. Identify your load balancer or proxy (AWS ALB, NGINX, Cloudflare). Confirm it supports weighted routing. This is the only prerequisite for Canary deployments.
- Day 3: The "One Service" Pilot. Pick the smallest, least critical microservice. Task one engineer with building a Blue-Green script for it. Do not try to boil the ocean. Start with a cup of tea.
The path to scale is paved with boring, repeatable systems.
You have mastered the mechanics of deployment. Now you must master the mechanics of the entire business.
THE FOUNDER’S OPERATING SYSTEM is the comprehensive blueprint for executives who refuse to rely on gut feeling. It creates the "system behind the systems." It aligns your engineering velocity with your revenue goals, your hiring pipeline, and your capital strategy.
Stop playing business by ear. Start operating by design.


